
Tutorijal - Forma za proveru jačine lozinke
")
")

Uvod
Tutorijal u kome ćemo prikazati postupak za izradu jednostavnog formulara za proveru jačine lozinke ....
.... biće dobra prilika da se posle kraće pauze ponovo usmerimo na praktične primere upotrebe regularnih izraza u JavaScript-u.
U prvom delu članka, pažnju ćemo posvetiti grafičkom dizajnu trake koja prikazuje jačinu lozinke, a u drugom delu, bavićemo se algoritmom koji proverava jačinu lozinke preko regularnih izraza.
Dizajn trake
Dizajn trake koja prikazuje snagu lozinke podrazumeva povezivanje nekoliko stavki koje su same po sebi jednostavne za implementaciju (a nije teško ni međusobno ih povezati i uskladiti):
- okvir i traka su obični
<div>elementi - okvir nema zadatu boju pozadine i ima border, dok je situacija sa trakom obrnuta (pozadina je u boji, a bordera nema)
- u smislu HTML strukture, okvir je noseći element (traka se nalazi unutar okvira)
- traka se poravnava uz levu ivicu okvira, a širina trake se zadaje u procentima (preko JS skripte)
- da se "ćoškovi" trake ne bi videli (budući da ćemo preko svojstva
border-radiuszaobliti ivice okvira), za okvir je potrebno koristiti svojstvooverflow, sa vrednošćuhidden
Napisaćemo prvo CSS kod koji odgovara navedenim zahtevima ....
Postavljanje elemenata
Za sam početak, poravnaćemo elemente jedan u odnosu na drugi, da bismo bolje sagledali njihovu međusobnu povezanost:
#lozinka_metar {
display: flex;
flex-direction: row;
justify-content: center;
align-items: center;
border: solid 1px #000;
}
#lozinka_metar_traka {
width: 180px;
height: 60px;
}
Elementi su sada raspoređeni na sledeći način:

U sledećem koraku, traka će biti: "zakačena" uz levu ivicu okvira, i (takođe), razvučena po visini, posle čega jedina bitna dimenzija trake postaje širina (na koju ćemo kasnije uticati preko JS-a).
Poravnanje trake u odnosu na okvir
Poravnanje trake u odnosu na okvir može se obaviti promenom vrednosti svojstava justify-content i align-items, a takođe ćemo i visinu okvira podesiti tako da ceo element poprimi oblik koji smo prethodno zamislili.
Ukoliko primenimo sledeći CSS kod ....
#lozinka_metar {
width: 100%;
height: 32px;
display: flex;
flex-direction: row;
justify-content: flex-start;
align-items: stretch;
border: solid 1px #000;
}
#lozinka_metar_traka {
width: 40%;
/*
visina više nije bitna
(traka se "proteže"
preko cele visine okvira)
*/
}
.... dobija se sledeći rezultat ....

.... i (u smislu grafičkog dizajna), preostaje samo da se zaoble ćoškovi na okviru i na traci (koja predstavlja "metar").
Zaobljavanje ivica okvira
Kao i do sada, zaobljavanje temena obavlja se preko svojstva border-radius * ....
#lozinka_metar {
....
border-radius: 16px;
}
.... a upotrebom CSS selektora sa prethodne slike, dobija se sledeći rezultat:
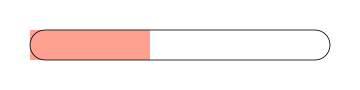
Uklanjanje "ćoškova" sa trake
Ćoškovi se mogu ukloniti sa trake na dva načina.
Kao prvo, može se i na ovom mestu koristiti atribut border-radius, ali, u tom slučaju moramo biti vrlo precizni:
#lozinka_metar_traka {
border-top-left-radius: 16px;
border-bottom-left-radius: 16px;
}
"Odsecanje" možemo obaviti i tako što ćemo na <div> elementu lozinka_metar pristupiti svojstvu overflow i zadati vrednost hidden (i reklo bi se da je u pitanju jednostavniji i elegantniji način):
#lozinka_metar {
....
border-radius: 16px;
overflow: hidden
}

Traka je sada spremna za povezivanje sa JS-om.
Povezivanje trake sa JS-om
U sledećem poglavlju razmotrićemo kako se algoritamskim putem može obaviti procena snage lozinke u odnosu na dužinu i prisustvo (tj. odsustvo) cifara i specijalnih znakova, ali - prvo je potrebno definisati osnovni mehanizam za pristup traci.
Funkcija za formatiranje prikaza trake prima kao argument "snagu" lozinke (koja može biti u rasponu od 0 do 100), i potrebno je samo da funkcija pronađe traku (preko DOM strukture), pristupi zatim svojstvu width, i zada vrednost u procentima, po pravilima CSS-a (brojčana vrednost promenljive snaga, pretvorena u nisku, spaja se sa niskom "%").
function formatiranjeMetar(snaga) {
let metar = document.getElementById("lozinka_metar_traka");
metar.style.width = snaga + "%";
}
Ako napravimo sledeći poziv ....
formatiranjeMetar(80);
.... očekivani rezultat možemo videti na donjoj slici ....

.... i sada (konačno) možemo da pređemo na JS i pozabavimo se postupcima za proveru jačine lozinke ....
Procena jačine lozinke preko regex-a
U funkciji za procenu jačine lozinke beležićemo samu jačinu lozinke, kao i listu nedostataka:
- za početak, smatraćemo da nedostataka nema, i stoga će promenljiva
snagaimati vrednost 100 a lista nedostataka biće prazna - potom treba izvršiti nekoliko provera, pri čemu svaka funkcija za proveru potencijalno može umanjiti snagu lozinke (u takvim slučajevima, u listu nedostataka takođe se unosi i odgovarajuća napomena)
- funkcije koje proveravaju pojedinačne nedostatke biće implementirane tako da vraćaju vrednost za koju treba redukovati snagu lozinke
- posle svih pojedinačnih provera, potrebno je ažurirati traku koja prikazuje snagu (onako kako smo videli na kraju prethodnog odeljka)
Osnovna funkcija ima sledeći oblik:
function ProveraLozinke() {
let lozinka = document.getElementById("forma_lozinka").value;
let lozinkaInfo = document.getElementById("lozinka_info");
let lozinkaMetar = document.getElementById("lozinka_metar_traka");
let snaga = 100;
let nedostaci = [];
snaga -= ProveraDuzina(lozinka, nedostaci);
snaga -= proveraBarJednoVelikoSlovo(lozinka, nedostaci);
snaga -= proveraBarJednaCifra(lozinka, nedostaci);
snaga -= proveraBarJedanSpecijalniZnak(lozinka, nedostaci);
formatiranjeMetar(lozinkaMetar, snaga);
if (snaga == 100) {
lozinkaInfo.innerHTML = "<li>Lozinka je ok</li>";
}
else {
lozinkaInfo.innerHTML = FormatiranjeIspisa(nedostaci);
}
}
Pošto smo postavili okvire, možemo se pozabaviti i pojedinačnim funkcijama za proveru nedostataka lozinke ....
Za proveru dužine lozinke može se koristiti i svojstvo niski length (već poznato od ranije), ali, budući da je provera dužine samo jedna stavka (i pri tom najjednostavnija), nećemo je "izdvajati", i sve provere, uključujući i proveru dužine, obavljaćemo preko regularnih izraza (preko JS funkcije match).
Takođe, napomenimo da iza redukcija ne stoji nikakva "nauka", već samo okvirna/iskustvena procena o tome koliko koja stavka utiče na lozinke u svakodnevnim uslovima (možete se naknadno opredeliti da promenite određene parametre, a možete dodati i druge mehanizme provere, ako smatrate da je neophodno).
Provera dužine lozinke
Provera dužine je jednostavna: dovoljno je proveriti da li se bilo koji znak ponavlja bar osam puta.
function ProveraDuzina(lozinka, lista) {
let obrazac = /.{8,}/;
if (lozinka.match(obrazac)) {
return 0;
}
lista.push("Dužina lozinke mora biti bar osam znakova");
return 50;
}
Ako funkcija match pronađe poklapanje, neće biti redukcije snage, dok će suprotnom redukcija biti 50 (krajnje opravdano, jer, iako lozinke velike dužine nisu obavezno sigurne, kratke lozinke obavezno jesu nesigurne).
Takođe, vidimo i kod koji će u listu nedostataka uneti odgovarajuću poruku o očekivanoj dužini lozinke (ako se nedostatak pojavi).
Provera prisustva specijalnih znakova
U nastavku, koristićemo ponešto drugačiji (tj, "zvaničniji") mehanizam provere u odnosu na prethodni odeljak.
Kao što znamo od ranije: ukoliko dođe do poklapanja, funkcija match vraća niz koji sadrži sve niske koje odgovaraju kriterijumu za pretragu (kriterijum je ovoga puta regularni izraz), dok je u suprotnom povratna vrednost null - i upravo je to razlog zašto je kod za proveru dužine lozinke u prethodnom odeljku mogao da "proradi" u bilo kojim okolnostima (u proveri uslova u if grananju, sistemska vrednost null tretira se kao logička vrednost false dok se "skoro sve ostalo" * tretira kao true).
Međutim, nadalje ćemo poklapanja smeštati u niz, koji će nositi naziv (upravo), poklapanja, i na kraju ćemo proveravati da li je broj elemenata niza veći od 0.
function proveraBarJedanSpecijalniZnak(lozinka, lista) {
let obrazac = /[\\`~!@#$%^&*()\-\_\\+\\=\\[\\]{}]/;
let poklapanja = lozinka.match(obrazac) || [];
if (poklapanja.length > 0) {
return 0;
}
lista.push("Lozinka mora sadržati bar jedan specijalni znak");
return 20;
}
Ako funkcija match vrati niz koji nije prazan, neće biti redukcije snage, dok će u suprotnom redukcija biti 20 (smatramo da je prisustvo bar jednog specijalnog znaka bitna stavka, ali, ne toliko bitna koliko i dužina).
Provera prisustva cifara
I ovoga puta funkcija match vraća (ili ne vraća?! :)), niz sa prepoznatim niskama (što će biti provereno), ali, klasa znakova u regularnom izrazu je drugačija ([0-9]), i prilagođena je pretrazi cifara:.
function proveraBarJednaCifra(lozinka, lista) {
let obrazac = /[0-9]/;
let poklapanja = lozinka.match(obrazac) || [];
if (poklapanja.length > 0) {
return 0;
}
lista.push("Lozinka mora sadržati bar jednu cifru");
return 15;
}
Ako funkcija match vrati niz koji nije prazan, neće biti redukcije snage, dok će u suprotnom redukcija biti 15.
Provera prisustva velikih slova
Verujemo da je čitaocima poznato od ranije da se velika slova engleskog alfabeta mogu tražiti preko klase znakova [A-Z], međutim, postoji i moderniji (i praktičniji) način.
Regularni izrazi mogu pristupati opštim svojstvima Unicode znakova, pa tako recimo izraz /\p{Lu}/gu praktično omogućava da se proveri da li određeni znak predstavlja veliko slovo:
\p- property (svojstvo)L- letter (slovo)u- 'uppercase' (veliko slovo)
function proveraBarJednoVelikoSlovo(lozinka, lista) {
let obrazac = /\p{Lu}/gu;
let poklapanja = lozinka.match(obrazac) || [];
if (poklapanja.length > 0) {
return 0;
}
lista.push("Lozinka mora sadržati bar jedno veliko slovo");
return 10;
}
Ako funkcija match vrati niz koji nije prazan, neće biti redukcije snage, dok će suprotnom redukcija biti 10.
Funkcija za formatiranje trake
Funkciji za formatiranje trake dodaćemo i pomoćnu funkciju za zadavanje boje u zavisnosti od jačine lozinke ....
function formatiranjeMetar(metar, snaga) {
metar.
style.
width = snaga + "%";
metar.
style.
backgroundColor = formatiranjeMetarBoja(snaga);
}
function formatiranjeMetarBoja(snaga) {
if (snaga < 40) {
return "#ffa181";
}
if (snaga < 60) {
return "#ffcf81";
}
if (snaga < 80) {
return "#fff781";
}
return "#c7ff6a";
}
.... posle čega preostaje samo da formatiramo ispis nedostataka lozinke (ukoliko lista nedostataka nije prazna).
Funkcija za formatiranje ispisa nedostataka lozinke
Pomoćna funkcija za formatiranje ispisa nedostataka lozinke podrazumeva prolazak kroz sve elemente liste, pri čemu se elementi uokviruju <li> tagovima:
function FormatiranjeIspisa(lista) {
let s = "";
for (let i = 0; i < lista.length; i++) {
s += "<li>" + lista[i] + "</li>";
}
return s;
}
Formular je sada kompletan, a rezultat ste već videli na samom početku (ako ste mislili da je u pitanju slika, slobodno se vratite i isprobajte formular (koji je potpuno funkcionalan)). :)
Ideje za dalje unapređenje
Postupak koji smo prikazali nije bez nedostataka i svakako se može dalje unaprediti (što može biti veoma zanimljiva vežba za samostalnu implementaciju), međutim, u praktičnom smislu, dodatna unapređenja bi bila: ili ne-previše-bitna (recimo, provera da li ima i više od jednog specijalnog znaka), ili bi se morao implementirati nezanemarljivo ozbiljan algoritam za prepoznavanje semantičkih obrazaca u tekstu.
Na primer, lako se može ustanoviti da li je korisnik pokušao da "prošvercuje" lozinku kao što je "AaaBbb123", ali zato nije skroz trivijalno implementirati algoritam koji bi proveravao da li je korisnik pokušao da "prođe" sa lozinkom kao što je "Aleksand4r!", "Programiranj3#" i sl (doduše, nije ni mnogo teško).
Sa druge strane, sistemi za registraciju sadrže (po pravilu) uputstva za kreiranje korektnih lozinki, pa - ako neko 'baš želi' da krši takva uputstva (pored svih saveta i na svoju štetu) - reklo bi se da mu se ipak mora dati sloboda da to i učini. :)
Za vežbu, probajte da samostalno dodate bar još neko sitnije unapređenje (od dodatnog isprobavanja opcija u fazi učenja, samo može biti koristi), a što se tiče "nepažljivo izabranih lozinki", to je problem koji (bar za sada), u praksi možemo rešiti samo "u lokalu", tako što ćemo sami koristiti adekvatne lozinke i (u skladu sa mogućnostima i bez nametanja), 'blago podsticati' prijatelje i poznanike da postupaju na sličan način. :)